阻塞队列与线程池机制
创建线程的方式
- 1.Thread
- 2.Runnable(实例化接口,重新run方法,放入Thread中执行)
为什么Callable方式不算?
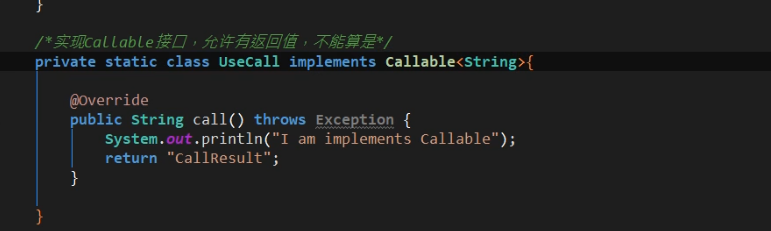
首先,我们都知道创建线程都需要通过Thread,那么我们来看一下Thread的构造函数
可以看到,Thread构造函数中压根就没有Callable类型的参数
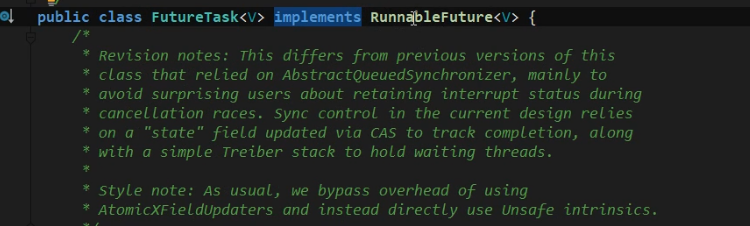
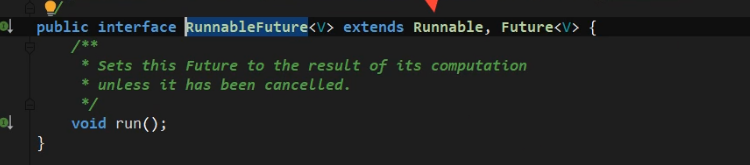
接着,我们再来看看Callable,Callable是继承自FutureTask
通过上面的源码截图,我们可以看出来Callable本质上还是Runnable的一种实现
CAS
Compare And Swap
提及CAS之前,我们先来提一下原子操作,原子操作就是一气呵成,中间不能被打断,学过操作系统的朋友应该和熟悉,没错,就类似于操作系统中的中断原语。
CAS原理
利用了现代处理器都支持的CAS的指令,循环这个指令,直到成功为止。
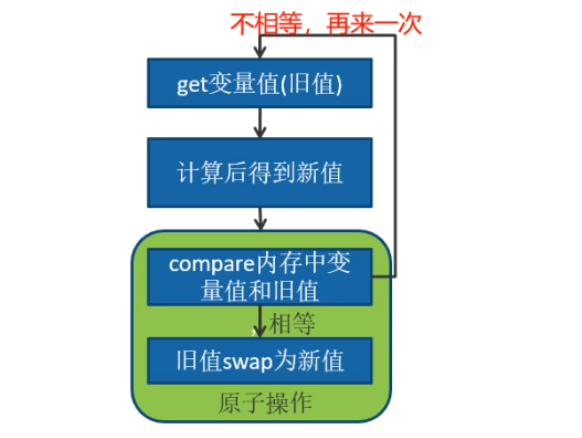
会有两个重要的属性变量,旧值与新值(需要更改的值),每次进入前都会用旧值与内存中的变量值进行比较,如果相同,就会用新值替换内存中的变量值,否则将再次循环上述过程。
CAS的问题
ABA问题
什么是ABA问题呢?
就是旧值为A,被替换为新值B,后面的线程又替换为新值A。再后面的线程对比其存储的旧值与内存中的值相等,但是它并不知道中间有个A->B->A的过程。
解决方案
通过打标识的方式标记:
1.AtomicMarkableReference->仅仅标识发生了ABA现象
2.AtomicStampedReference->可以知道发生了几次ABA现象
开销问题
CAS是一个不断循环检测的过程,毫无疑问,这将带来一定的开销。
只能保证一个共享变量的原子操作
- jdk中相关原子操作类的使用
- 更新基本类型:AtomicBoolean,AtomicInteger,AtomicLong
- 更新数组:AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray
- 更新引用类型:AtomicReference,AtomicMarkableReference(只关心该没改过),AtomicStampedReference(还关心改过几次)
有些时候对于某些简单的操作采用加锁的话未免有些过重了,可以采用原子类型如果你需要改变多个变量,可以进行封装,通过AtomicReference来管理。
线程池机制
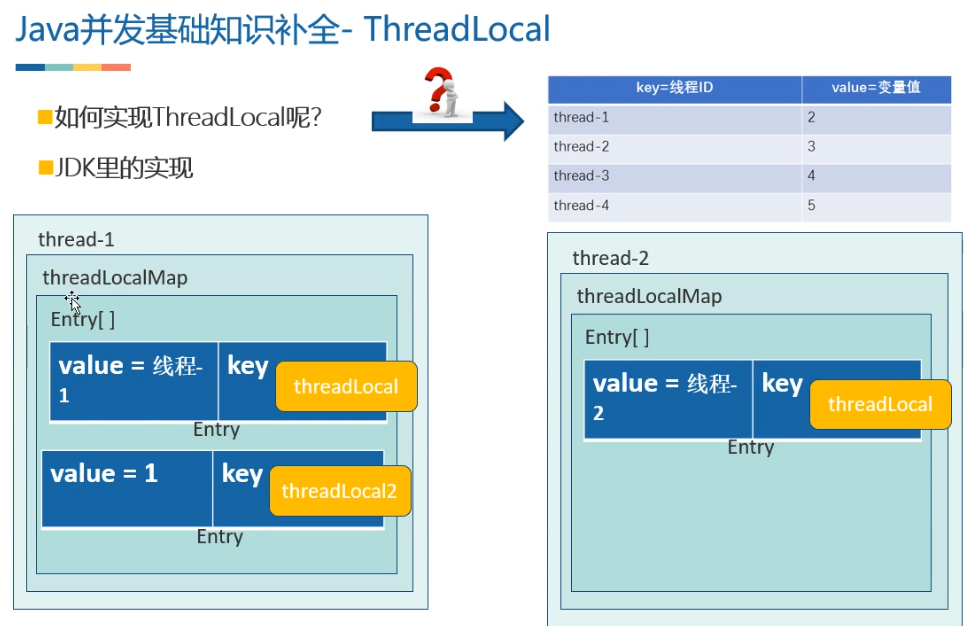
ThreadLocal简介
线程本地变量,也有些地方叫做线程本地存储,其实意思差不多。ThreadLocal可以让每个线程拥有属于自己的变量的副本,不会和其他线程的变量副本冲突,实现了线程的数据隔离
线程池简介
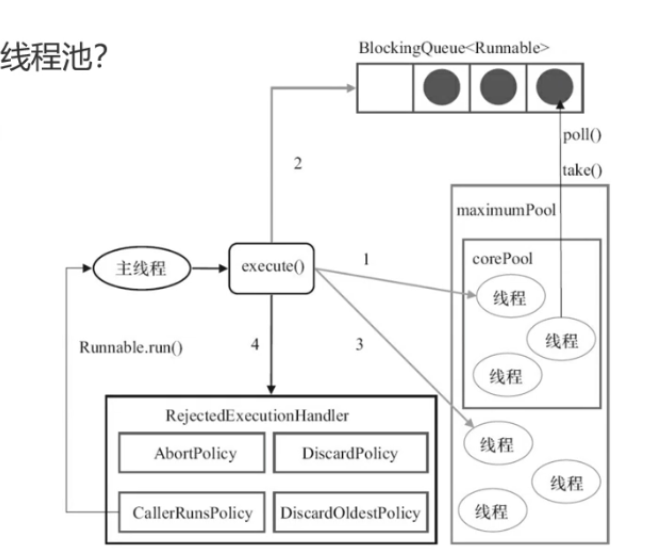
什么是线程池?为什么要用线程池?
- Thread线程属于操作系统的资源,消耗CPU、内存 ->降低资源消耗
- 线程有创建、执行、销毁的时间,所以为什么不事先准备好呢?->提高响应度
- 所以需要一个策略机制来管理线程->提高线程的可管理性
线程池的参数
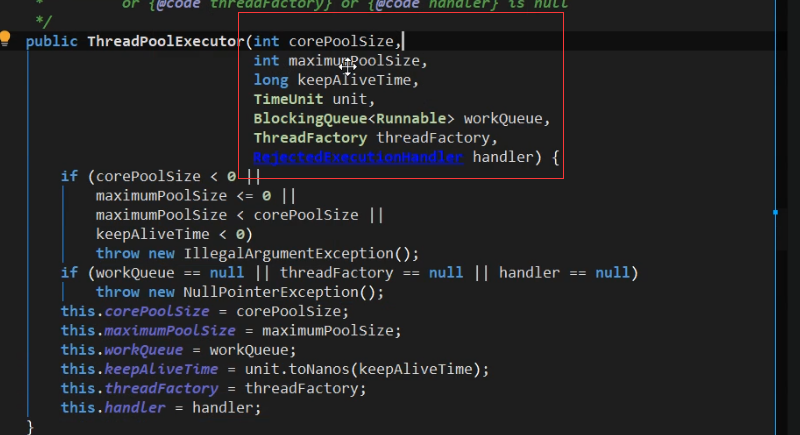
keepAliveSize和TimeUnit这俩参数控制空闲线程存活的时间
ThreadFactory对创建线程时做这些微调工作
RejectedExecutionHandler 拒绝策略(阻塞队列满,任务数超过了最大线程数,那么就会拒绝)
- DiscardOldestPolicy 抛弃最老的,也就是队列队首的任务
- AbortPolicy 直接抛出异常
- CallerRunsPolicy 谁调用谁执行
- DiscardPolicy 丢弃最新提交的任务
当然也可以自己实现接口自定义拒绝策略
阻塞队列BlockingQueue
阻塞队列
- ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列
- LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列
- PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列
- DelayQueue:一个使用优先级队列实现的无界阻塞队列
- SynchronousQueue:一个不存储元素的阻塞队列
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列
这里以okhttp中的实用场景对其中几种做简介:
在OkHttp的分发器中的线程池定义如上,其实就和 Executors.newCachedThreadPool()创建的线程一样。首先核心线程为0,表示线程池不会一直为我们缓存线程,线程池中所有线程都是在60s内没有工作就会被回收。而最大线程Integer .MAX_VALUE与等待队列synchronousQueue的组合能够得到最大的吞吐量。即当需要线程池执行任务时,如果不存在空闲线程不需要等待,马上新建线程执行任务!等待队列的不同指定了线程池的不同排队机制。一般来说,等待队列BlockingQueue有: (ArrayBlockingQueue 、LinkedBlockingQueue 与synchronousQueue 。
假设向线程池提交任务时,核心线程都被占用的情况下:
ArrayBlockingQueue :基于数组的阻塞队列,初始化需要指定固定大小
当使用此队列时,向线程池提交任务,会首先加入到等待队列中,当等待队列满了之后,再次提交任务,尝试加入队列就会失败,这时就会检查如果当前线程池中的线程数未达到最大线程,则会新建线程执行新提交的任务。所以最终可能出现后提交的任务先执行,而先提交的任务一直在等待。
LinkedBlockingQueue :基于链表实现的阻塞队列,初始化可以指定大小,也可以不指定。
当指定大小后,行为就和ArrayBlockingQueue一致。而如果未指定大小,则会使用默认的Integer.MAX_VALUE作为队列大小。这时候就会出现线程池的最大线程数参数无用,因为无论如何,向线程池提交任务加入等待队列都会成功。最终意味着所有任务都是在核心线程执行。如果核心线程一直被占,那就一直等待。
SynchronousQueue :无容量的队列。
使用此队列意味着希望获得最大并发量。因为无论如何,向线程池提交任务,往队列提交任务都会失败。而失败后如果没有空闲的非核心线程,就会检查如果当前线程池中的线程数未达到最大线程,则会新建线程执行新提交的任务。完全没有任何等待,唯一制约它的就是最大线程数的个数。因此一般配合Integer.MAX_VALUE就实现了真正的无等待。
但是需要注意的时,我们都知道,进程的内存是存在限制的,而每一个线程都需要分配一定的内存。所以线程并不能无限个数。那么当设置最大线程数为Integer.MAX_VALUE时,OkHttp同时还有最大请求任务执行个数: 64的限制。这样即解决了这个问题同时也能获得最大吞吐。
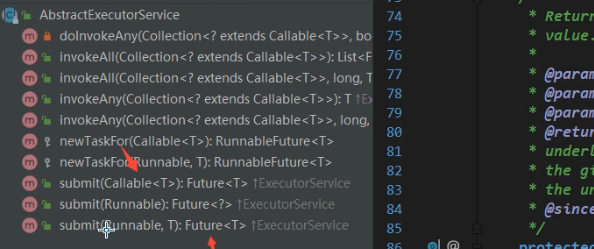
两种线程池的提交任务的方法
execute(不关心有无返回结果)
submit
线程池的关闭
shutdown 尝试关闭一个线程,把当前没有执行任务的线程中断
shutdownNow 不管有没有执行任务的线程,都尝试中断
但是不一定成功 所谓线程的中断是一个协作机制 看任务执行方
合理配置线程池资源
任务特性
CPU密集型 纯计算
配置最大线程数不要超过机器的CPU核心数(Runtime.getRuntime())顶多+1(保证核心线程有事做),否则切换线程带来时间浪费
IO密集型 与网络、读取磁盘等IO操作相关的
最大线程数:机器的CPU核心线程数*2(推荐的经验值)
混合型 兼并上面两者
如果两者的执行时间相差不大,拆分成两个线程池专门处理各自类型
如果两者相差很大,不用拆分(谁大配置谁)。
核心线程数,看业务(详情参考Okhttp)
 微信
微信 支付宝
支付宝



